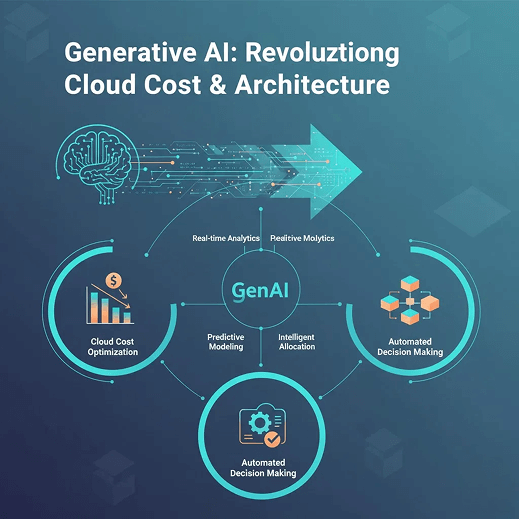
Introduction: GenAI’s Unseen Impact on Cloud Economics
Generative AI is no longer just an application feature; it is now a primary driver of cloud architecture decisions and spend. Training, fine-tuning, inference, vector databases, and GPU clusters are reshaping how engineering, data, and FinOps teams think about infrastructure and governance. GenAI is effectively rewriting cloud cost frameworks, not merely adding new workloads on top of legacy designs.
GPU-Based Infrastructure Is the New Default for GenAI
Why GPUs Change Cloud Cost Dynamics
GenAI workloads such as LLMs, embeddings, and diffusion models rely heavily on GPU or TPU accelerators rather than CPUs, which dramatically increases the baseline cost per hour of compute. Because GPUs are so much more expensive, idle time on GPU clusters leads to immediate cost leakage and makes utilization one of the most important efficiency levers.
Architectural Considerations
To control spend, teams are moving from “always-on” GPU clusters to dynamically provisioned infrastructure that spins up for training or traffic bursts and tears down afterward. GPU autoscaling, job-batching for inference, spot or preemptible GPU instances, and multi-tenant GPU pooling all help improve utilization and reduce stranded capacity.
Cost Outcomes
When these practices are in place, organizations see lower idle GPU costs, higher overall utilization, and more predictable GPU budgets aligned to real workload patterns rather than overprovisioned buffers.
Model Choice Directly Impacts Cloud Spend
Large vs Small Models - Cost Implications
Very large models with tens of billions of parameters significantly increase inference latency and per-request cost. Many teams are discovering that smaller, domain-specific, distilled, or quantized models can deliver 80–90% of the quality at a fraction of the compute footprint.

Architectural Strategies
Architecturally, this is driving multi-model routing where simple tasks hit lightweight models and only complex or high-value requests go to the largest LLMs. Teams are also weighing fine-tuning versus retrieval-augmented generation (RAG), containerized or serverless model hosting, and tradeoffs between hosted API models and self-managed deployments based on cost, latency, and compliance.
Cost Outcomes
These strategies reduce inference bills, improve performance-per-dollar, and provide the flexibility to scale GenAI features without uncontrolled cost spikes.
RAG and Vector Architecture Introduce New Data and Storage Costs
New Data Cost Centres Introduced by GenAI
RAG has become a core pattern for enterprise GenAI, bringing vector databases and embeddings to the center of data architecture. This introduces new cost centers: vector storage, frequent I/O for chunking and embedding generation, and hot storage requirements for low-latency retrieval.
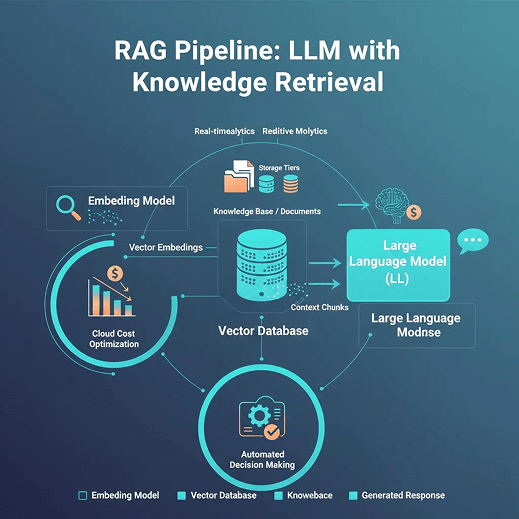
Architectural Optimisations
Cost-efficient RAG architectures use tiered storage (hot–warm–cold), embedding caching, document deduplication, and tuned chunk sizes to reduce the number and size of vectors. Scheduled re-indexing during off-peak windows also cuts continuous indexing overhead and can leverage cheaper compute pricing.
Cost Outcomes
These optimizations shrink storage footprints, lower I/O-related costs, and improve query performance by keeping only the most critical data on high-performance tiers.
GenAI-Aware FinOps and Cloud Cost Governance Are Now Essential
Why GenAI Breaks Old FinOps Models
Traditional FinOps was designed for relatively stable CPU and storage usage, but GenAI introduces highly variable GPU workloads and token-based pricing that are harder to predict. Shared AI infrastructure across multiple teams makes accurate cost attribution and governance even more critical.
Architectural and Operational FinOps Measures
Modern practice emphasizes real-time dashboards for GPU utilization and inference cost, cost-per-request tracking, resource tagging for LLM and RAG components, and guardrails such as token limits and quotas. CI/CD pipelines now incorporate cost checks, blocking or flagging deployments that exceed defined spend thresholds.
Cost Outcomes
With GenAI-aware FinOps, organizations achieve more predictable monthly budgets, controlled inference spikes, and clear team-level accountability for spend.
Hybrid and Multi-Cloud Architectures Are Becoming Standard for GenAI
Why Multi-Cloud Fits GenAI Workloads
GenAI workloads benefit from different clouds strengths: some offer cheaper GPUs, others specialized AI services, and some regions better latency or compliance options. This makes single-cloud strategies increasingly limiting for cost and flexibility.
Architectural Patterns Emerging in 2026
Common patterns include training on clouds or regions with cheaper accelerators and deploying inference on platforms with stronger global edge networks. Data platforms like Snowflake or Databricks often sit alongside inference environments on AWS, Azure, or GCP, while hybrid setups mix on-prem GPU clusters for predictable workloads with cloud bursts for peaks. Multi-cloud routing further optimizes cost-per-token and data locality.
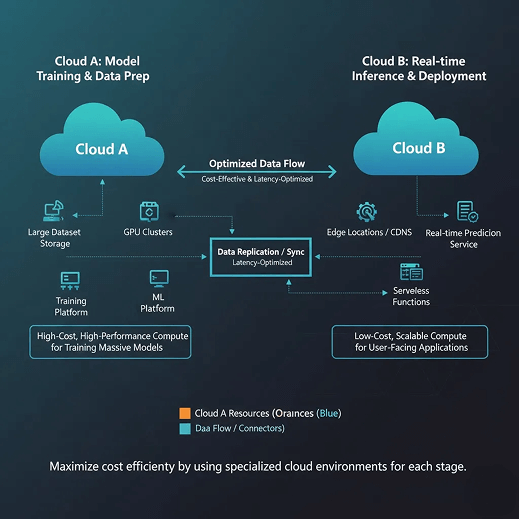
Cost Outcomes
These patterns enable cost arbitrage across providers, reduce training and inference costs, and increase flexibility to scale globally without heavy vendor lock-in.
The Pace Wisdom Solutions POV
At Pace Wisdom Solutions, engineering teams get a partner focused on designing AI-ready cloud architectures that deliver real performance without uncontrolled cost spikes. The core focus spans cloud modernization, RAG optimization, MLOps, vector architecture design, GPU governance, and FinOps implementation, helping enterprises bring GenAI into production with confidence and cost discipline.
By combining deep expertise in cloud-native engineering with practical experience in GenAI workloads, Pace Wisdom helps organizations map workloads to the right infrastructure, tune models and pipelines, and embed cost governance directly into their platforms and processes.
Conclusion: GenAI Isn’t Just Changing Apps - It’s Changing Cloud Economics
GenAI is reshaping cloud architecture strategy from the ground up, influencing everything from GPU provisioning and model selection to data architecture, FinOps, and multi-cloud design. The organizations that win in 2026 will be those that intentionally redesign infrastructure around these realities rather than treating GenAI as a bolt-on feature.
GenAI will only get more capable and more expensive, unless businesses reimagine cloud architecture through an efficiency-first lens, with clear governance and cost-aware design. With the right approach and partners like Pace Wisdom Solutions, enterprises can turn GenAI from a cloud cost risk into a strategic, scalable advantage.